Finding and Fixing Hotspots Through Monitoring
Published on January 16, 2019/Last edited on January 16, 2019/4 min read

Matt Hicks
Web Developer at BrazeReal-time segmentation is a part of every product offered by Braze. Our customers want messages going to their users only when they are relevant and timely. But once you build a product and put it out into the world, customers will find all kinds of ways to use it that were never considered. Building your system for easy monitoring and modularity lets you react to these use cases as they are uncovered.
One of the tools we use for monitoring is New Relic. It gives us a high-level view of how many resources our databases are using, and allows us to drill deeply into specific traces through our stack. Braze receives data from an SDK installed on devices and websites all across the world; this data gets processed through Sidekiq, a background job processor. In March, we started seeing problems with the main job that processes device data for one particular customer. This job updates the Braze database view of a user and checks to see if they have taken any actions that would trigger Braze to send them a push notification, email, or other type of message. The New Relic graph of the time this job was taking for one particular customer looked like this:
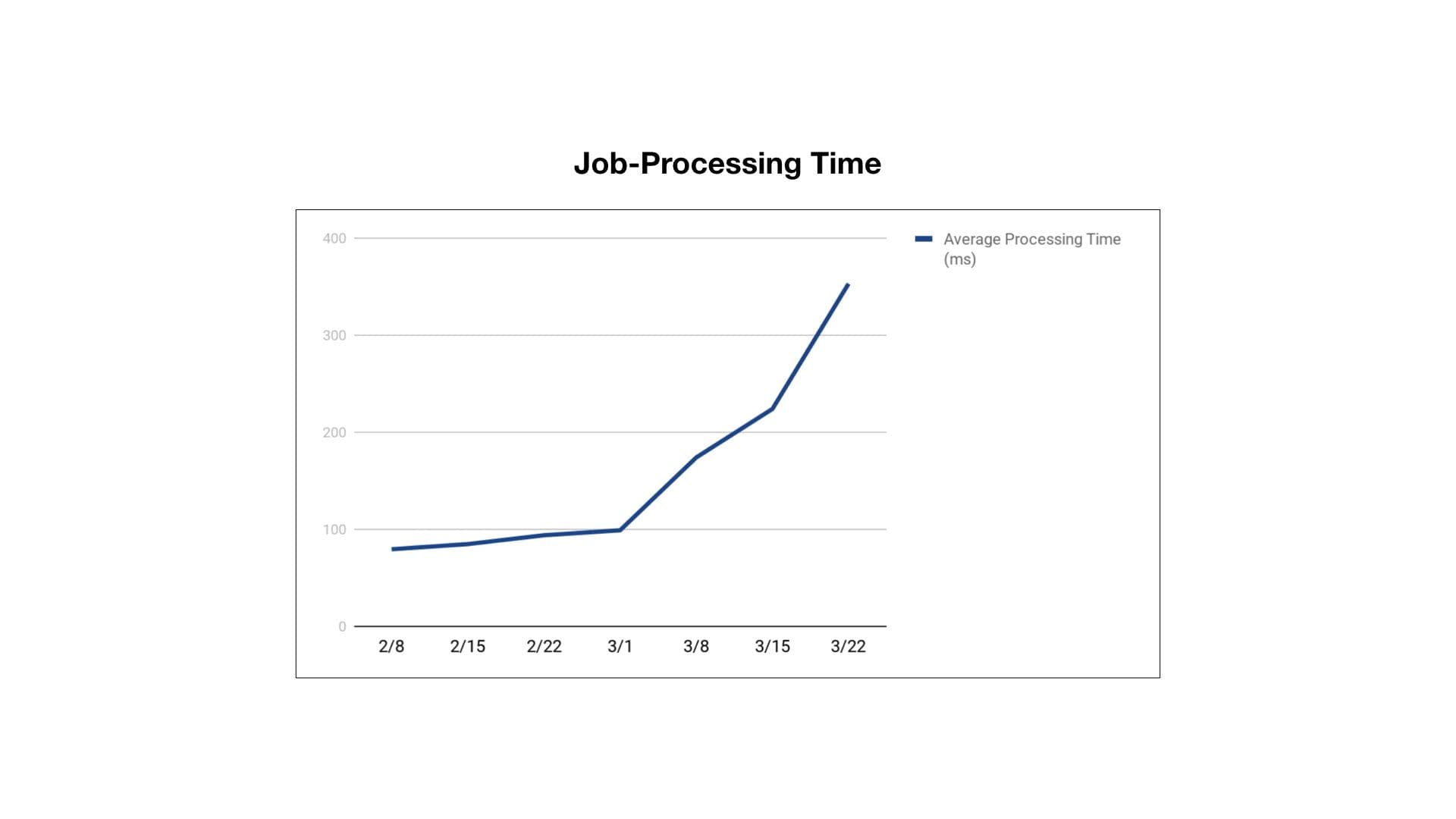
Job-processing time for this customer had gone up over 4x in a 45-day time period! To keep processing time stable, we needed to add a lot more worker servers, which increased our costs. Another graph gave us a hint as to what might be happening:
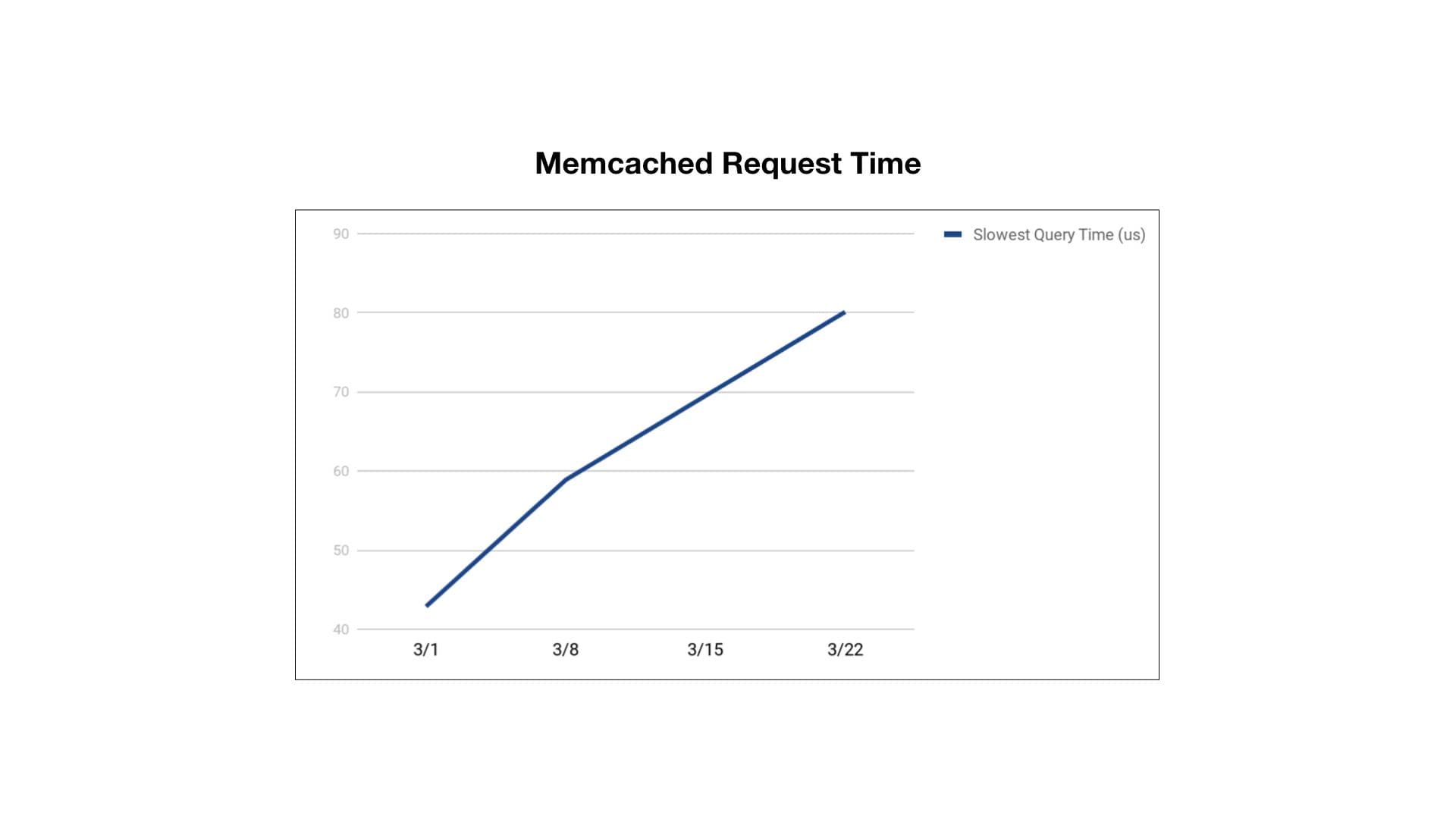
The slowest response times for getting data from Memcached had doubled. We use Memcached heavily for taking load off our primary datastores, so this was a wise path to explore. Since Memcached is a simple key-value store, we started to look for keys that had large values stored inside them. By debugging and tracing the codepath for a single request, we found the problematic key associated with the customer’s use of our Canvas product.
Canvas is a way to send a user on a guided journey with messages along the way. Canvas processes billions of messages a month and can support journeys with hundreds of steps. The platform uses an event-driven architecture to move users along a path. Events come in through the Braze SDK (and other sources), moving and possibly messaging users. Each step can be filtered using Braze’s real-time segmentation capabilities.
When we first built Canvas we made the assumption that all the segments applying anywhere along any Canvas could be stored at one key in Memcached. This turned out not to be the case for the customer who was causing performance issues. They had many large Canvases, with each step having a slightly different criteria for user segmentation. All these criteria were stored in one large serialized object (a hash with a step id pointing to the criteria for it) at one key in Memcached. However, given a user’s place in a Canvas, we can know which steps they could possibly receive next. Fetching information about all possible steps from Memcached ends up being unnecessary—and caused increased network traffic and CPU load.
To fix this we needed to change our cache structure and fetching strategy. Rather than having one key per Canvas with all possible segmentation information, we thought of adding a cache key for each step only containing the information for itself. Our code was modular enough to allow this to be a straightforward change. One thing we had to consider was what to do on a cache miss.
Our first thought was that fetching all the step information and putting it into the cache could be more performant. The idea being that if some of the steps are needed, the Canvas is active and all the steps might be needed soon. We deployed this change and did not see the results we wanted. Jobs that had a cache miss ended up taking too long from doing work that wasn’t needed at that instant. We made one last tweak to just fetch the data for the missing steps, and our performance time normalized to the level to where it was before March.
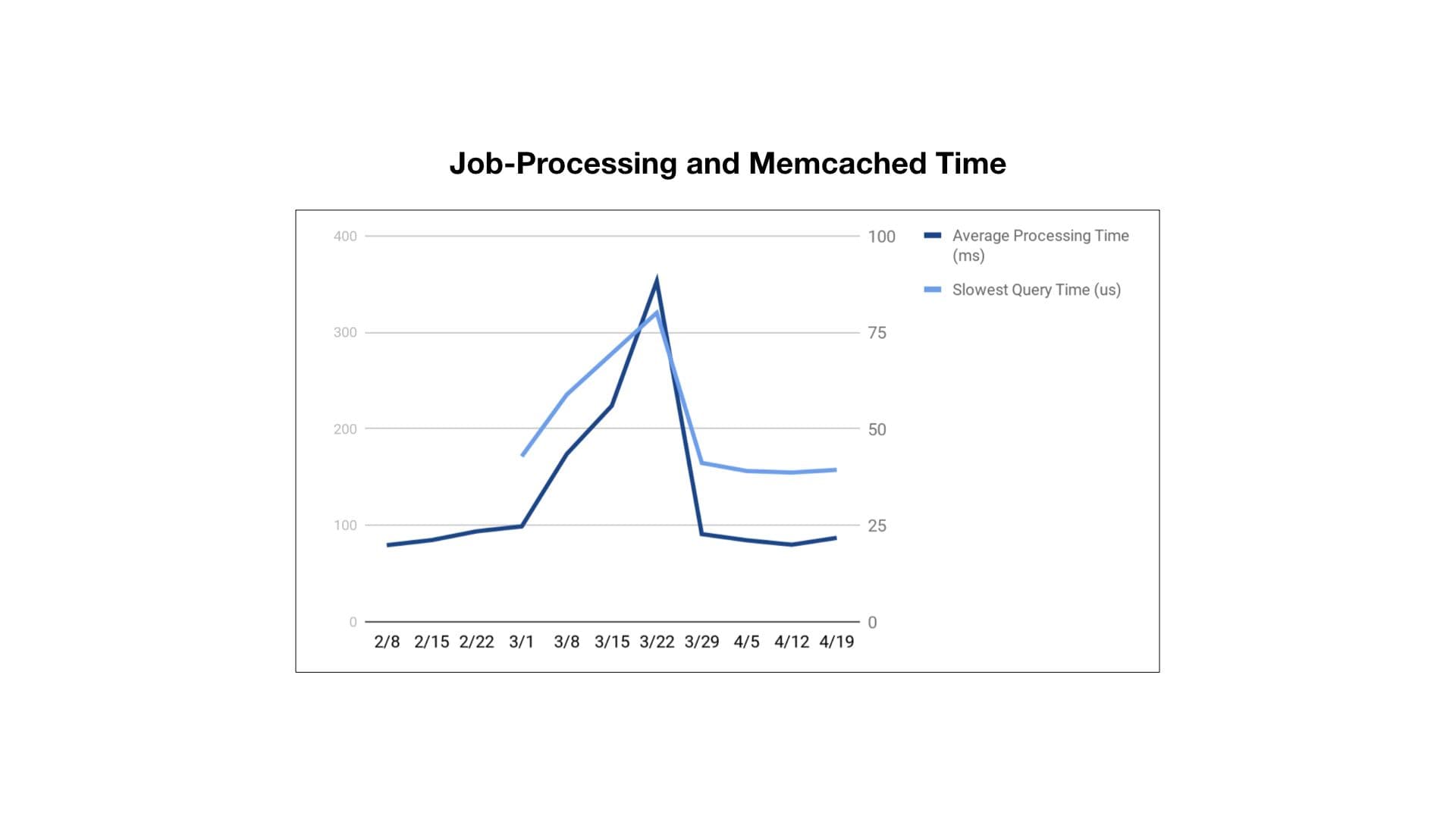
Users of your software will also stretch it to its limits and find ways of using it that you never anticipated. Being able to monitor your system and adjust your assumptions to actual real-world use is a huge key in designing a scalable process. In our case, we had enough monitoring to be able to pinpoint the bottleneck and swap out code to handle a new way our users were setting up their Canvas.
Anything else?
If you're interested in working with a team and a product built to creatively problem-solve, then you should definitely check our job board!
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
View the Blog
How behavioral marketing turns data into personalized experiences

Team Braze
Are you AI-savvy enough to survive? A wake-up call for CMOs
Team Braze

What are contextual bandits? The AI behind smarter, real-time personalization