Scaling New Heights: How Braze Uses Kubernetes to More Efficiently Handle Dynamic Workloads
Published on November 27, 2024/Last edited on November 27, 2024/8 min read


Saba Jamalian
Site Reliability Engineer, BrazeOne defining characteristic of the Braze platform is that it operates efficiently at an enormous scale. During the calendar year 2023, for instance, brands used Braze to send more than 2.6 trillion messages and other Canvas actions and to make over 7.5 trillion API calls. However, this usage can shift significantly not just from week to week, but from minute to minute, depending on what our customers are looking to achieve.
To give our system the flexibility it needs to operate successfully even under intense workloads, Braze takes advantage of autoscaling—that is, the ability to automatically scale capacity up or down based on current or anticipated needs. To continue upleveling our autoscale capabilities, Braze began experimenting with using the open-source Kubernetes (K8s) platform back in 2016. Now, eight years later, K8s has become a core part of the Braze platform's software infrastructure, supporting our customers' ability to understand, reach, engage, and build relationships at a massive scale.
In this piece, we’ll explore the factors that influenced Braze to leverage K8s to handle dynamic workloads, as well as some specifics around how we’re taking advantage of this technology to make our system more flexible, performant, and scalable.
Why Braze decided to transition to Kubernetes
Prior to our move to Kubernetes, the Braze platform ran on Amazon Web Services (AWS) Elastic Compute Cloud (EC2) Auto Scaling Groups, a collection of virtual servers that provided the foundation of our product’s demand-scaling capabilities.
To allow Braze to dynamically adjust the amount of data processing and messaging sending that our system is carrying out, tens of thousands of these servers were autoscaled using thousands of autoscale groups (ASGs) based on real-time demand. This approach also took advantage of automation powered by Chef, an open-source DevOps configuration tool, and Terraform, an open-source infrastructure-as-code provisioning software, at a global scale across multiple regions.
But as the dynamic nature of Braze workloads grew to the point where our systems were consistently handling tens of billions of requests and jobs on a daily basis, it became clear that we needed to investigate a more robust and efficient solution for handling our auto scale needs. In particular, we knew that we needed a solution that could support multiple cloud providers and enable rapid deployments and releases.
Our research into what technologies would best meet our need for more advanced features led us to Kubernetes. We decided to migrate to K8s because of its robust self-healing capabilities, improved resource utilization, and streamlined configuration management. This transition made it possible for us to handle our dynamic workloads more efficiently, a major consideration given the scale that Braze operates at, and simplified our deployment and operational processes by deprecating Chef in favor of cloud-native toolsets.
How Kubernetes supports handling of dynamic workloads
While we were bullish on Kubernetes’ ability to help us improve the efficiency of our systems, it was important to us that we verify K8s positive impact on the quality of the services we offered. To do that, we defined a particular set of service-level objectives (SLOs) and indicators regarding both application performance (e.g. latency, processing rate, job duration) and infrastructure costs. To account for the growth in requests while the migration project was in progress, we defined a cost variable that measured infrastructure spending based on the number of completed processes (e.g. API requests handled, messages sent) and requests.
When we talk about the Braze core platform, we’re referring to a Ruby monolithic application that handles three distinct types of workloads: Work associated with the Braze dashboard, Braze APIs, and Braze workers. In particular, the latter two have the highest rate of requests and can provide the clearest picture of the gains that come with migrating to Kubernetes.
Braze workers: Efficiently processing asynchronous tasks
The Braze platform manages asynchronous workloads through Sidekiq, which is a background processor for Ruby. These workloads, which sit across various queues powered by Redis, an in-memory data store, demand a scaling solution that’s capable of adapting to satisfy various metrics, including latency, job processing rates, and queue size trends.
To tackle this, we used Golang and the Kubernetes Operator SDK to develop a custom application named Arbiter. With Arbiter, we can autoscale deployments for the platform worker in Braze, adjusting resources on a per-tenant and per-Redis shard basis. This approach resulted in an application that’s capable of efficiently managing and processing approximately 30 billion Sidekiq jobs per day, tailored to fit the specific needs of each tenant and to minimize the demands placed on our infrastructure.
To give a better sense of how this all works, this chart illustrates the number of autoscaled replicas dedicated to one tenant that are processing tasks from one particular shard during a 30-minute window:
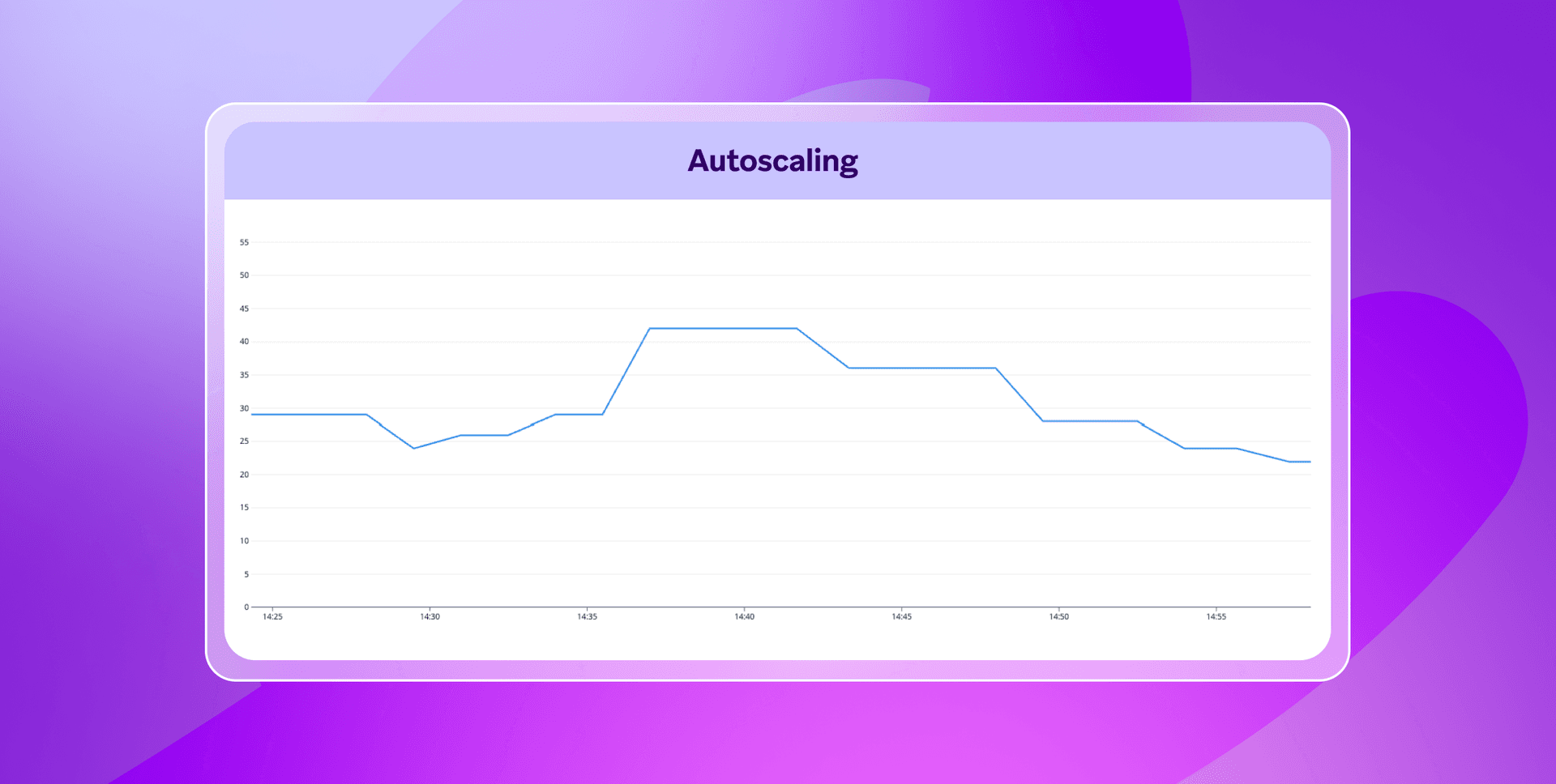
Arbiter leverages a decision engine that’s capable of outlining actions to take (e.g. scaling up, scaling down, or no operation) in response to trends associated with queue size, processing rate, and latency relative to our system’s latency toleration levels.
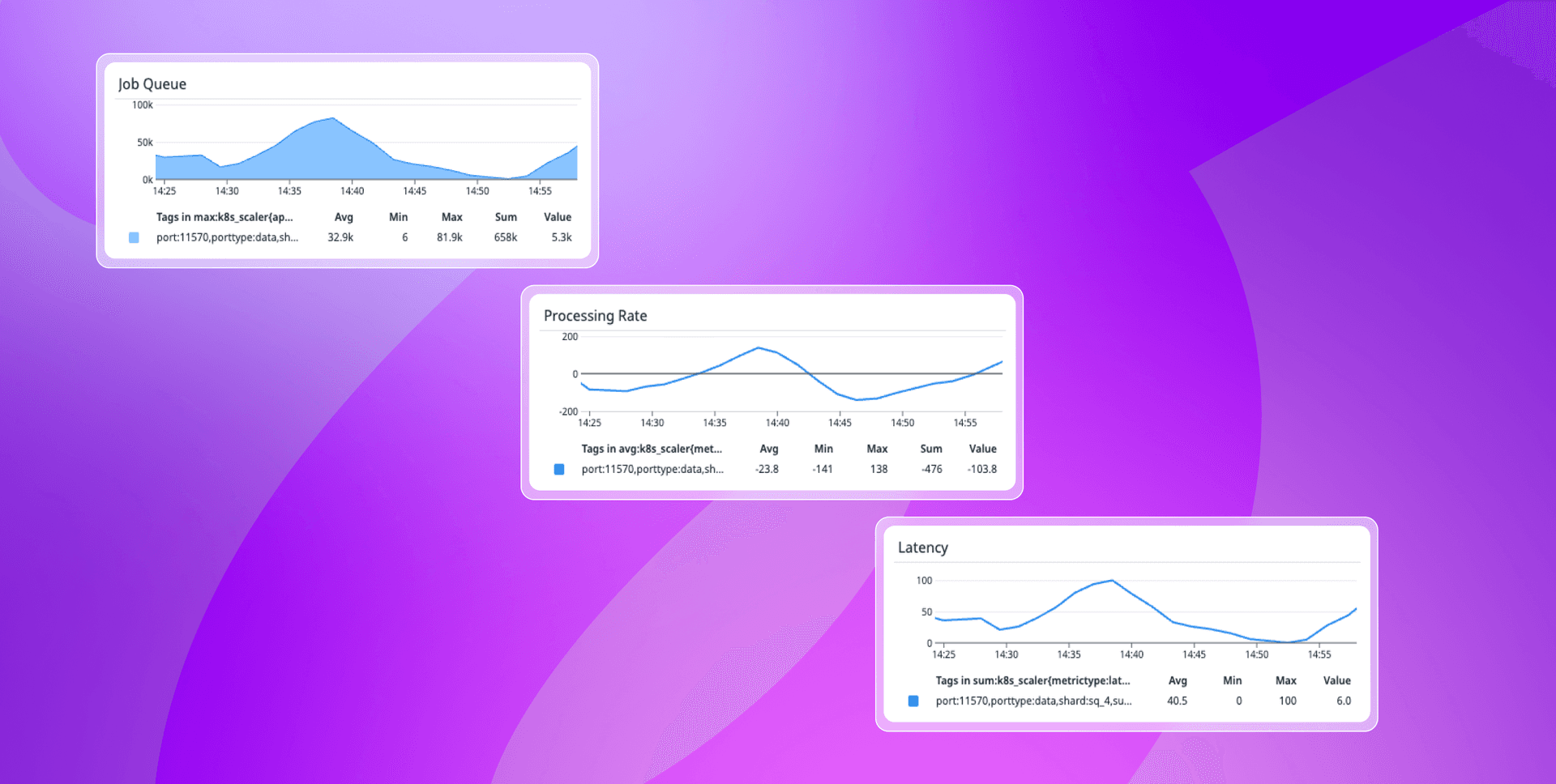
These automations don’t happen in a vacuum. In instances where the decision engine recommends a change be made in the number of replicas, the calculation that determines the resulting replica counts will be impacted by a set of tenant-specific parameters.
In the example below, the tenant has defined the following configurations as a K8s custom resource definition (CRD), allowing them to be used to inform the automation that could occur:
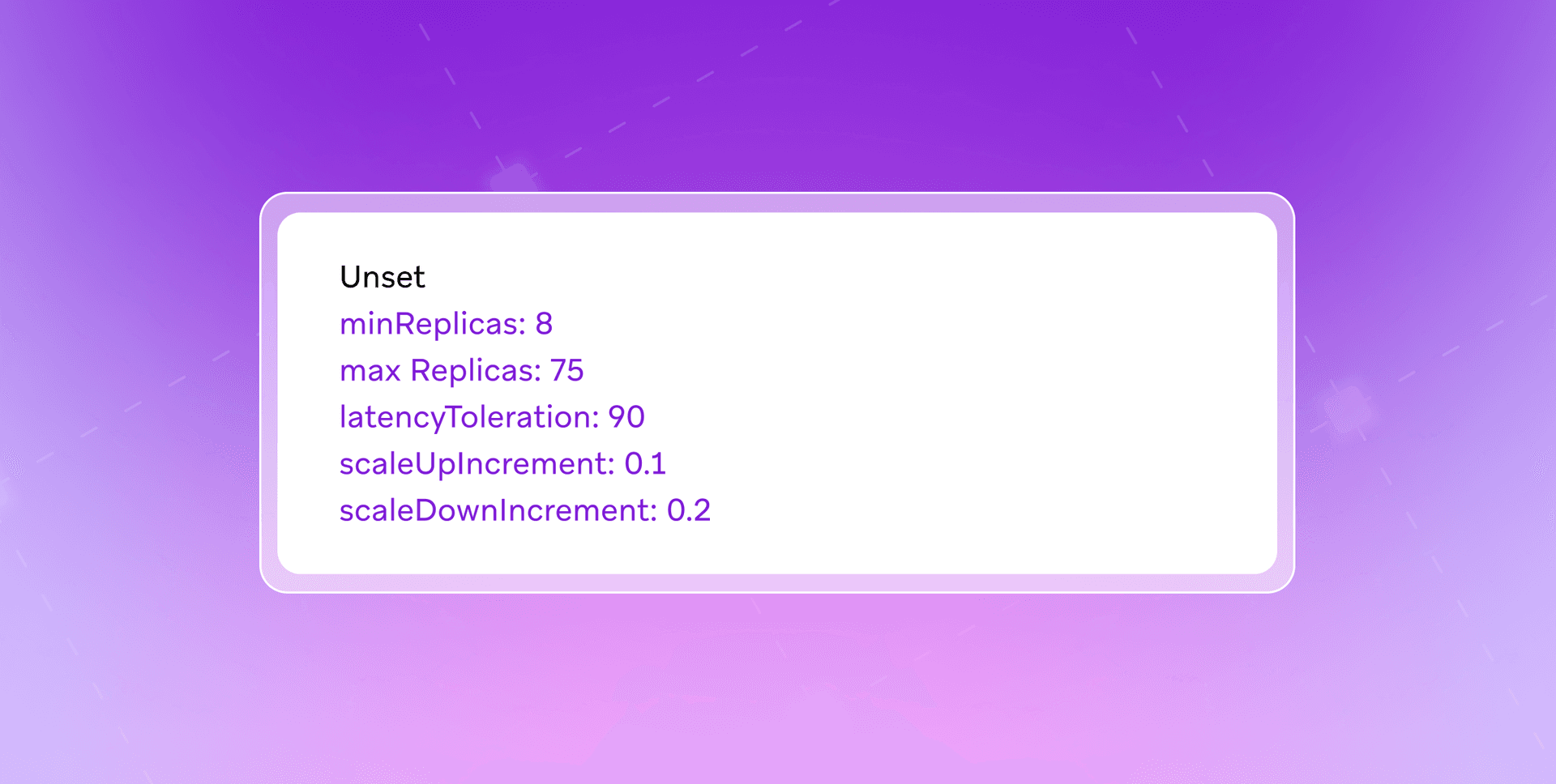
In this instance, Arbiter’s controller will periodically reconcile the tenant’s CRD with its deployment, then calculate the desired replica counts by following a formula:

By making these sorts of robust, nuanced automation possible, K8s has allowed us to more efficiently manage and deploy workers in connection with our infrastructure needs. That doesn’t just help save time and money—it also preserves resources and makes our systems more resilient in the face of growing processing and message sending demands from our customer base.
Braze APIs: Powering responsive and reliable service
Workers aren’t the only place where the Braze platform needs to be able to operate efficiently at a massive scale. Our Braze APIs are designed to handle a staggering 400,000 requests per second, reflecting the massive usage of our APIs by Braze customers and other systems. These requests come from two main sources:
- SDK calls from various client types
- Direct REST calls to our API endpoints
Ensuring that this component of our platform can scale and remain flexible is an essential part of providing a responsive and reliable service to our users.
In order to scale this component, we knew we needed to introduce a layered approach. Today, each one of our API fleets is segmented for specific request types and sits behind an autoscaled ingress controller and an AWS Network Load Balancer (NLB). The autoscaling associated with our Platform API fleet is now meticulously managed by Kubernetes Horizontal Pod Autoscalers (HPAs), allowing us to seamlessly monitor three vital metrics: Request counts, error rates, and P95 duration (RED metrics).
Leveraging Kubernetes in this way supports each fleet’s ability to dynamically adapt to the demands placed on it, maintaining optimal performance and reliability. Metrics are collected by Prometheus adapters and assessed in comparison to the targets set within each respective HPA to determine adequate replica count.
You can see that played out in the following graph. Here, the blue line indicates the number of requests per second captured at ingress, while the red line represents the autoscaled number of replicas associated with a specific application in one particular fleet and regional cluster.
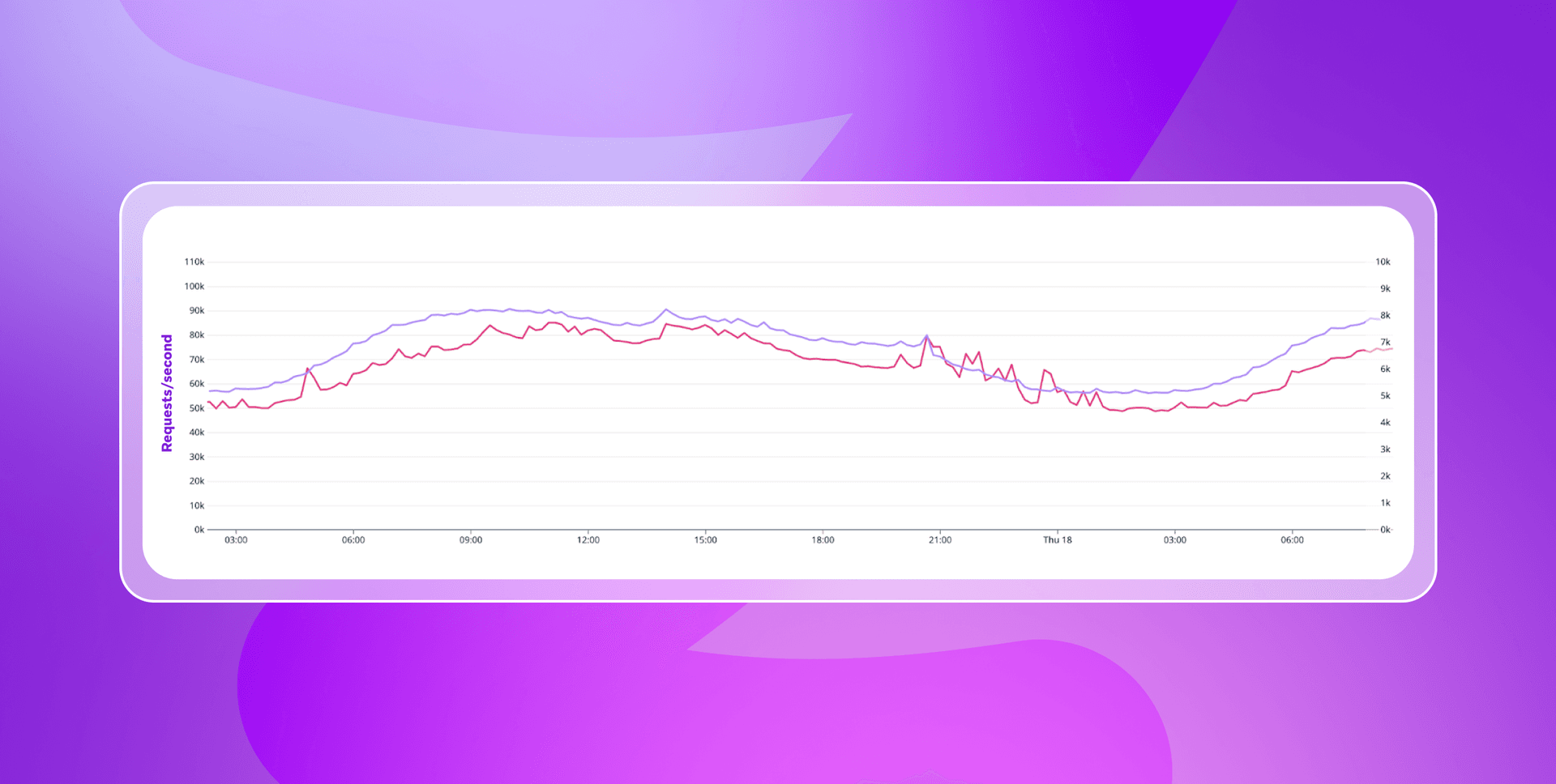
One particular challenge with the Braze APIs? Finding effective ways to handle the spikes in traffic. While our infrastructure is sized to be able to handle regular spikes in traffic gracefully, we’ve observed situations where a specific burst in requests could increase our traffic volume by 4 to 6X in a matter of minutes. Because we have access to those RED metrics, we’re able to autoscale as needed, allowing us to handle those situations with grace.
Final thoughts
As Braze continues to scale, we believe the decision to migrate to K8s marks a major strategic advancement toward a more responsive, powerful, and efficient infrastructure. By leveraging Kubernetes’ dynamic scaling capabilities and cloud-native toolsets, Braze is able to comfortably handle billions of requests—both in real-time and asynchronously—on a daily basis.
Interested in learning more about what this infrastructure is able to support? Read on to learn how Braze powers marketing sophistication at a massive scale.
Forward Looking Statements
This blog post contains “forward-looking statements” within the meaning of the “safe harbor” provisions of the Private Securities Litigation Reform Act of 1995, including but not limited to, statements regarding the performance of and expected benefits from Braze and its products, including as a result of utilizing Kubernetes. These forward-looking statements are based on the current assumptions, expectations and beliefs of Braze, and are subject to substantial risks, uncertainties and changes in circumstances that may cause actual results, performance or achievements to be materially different from any future results, performance or achievements expressed or implied by the forward-looking statements. Further information on potential factors that could affect Braze results are included in the Braze Quarterly Report on Form 10-Q for the fiscal quarter ended July 31, 2024, filed with the U.S. Securities and Exchange Commission on September 6, 2024, and the other public filings of Braze with the U.S. Securities and Exchange Commission. The forward-looking statements included in this blog post represent the views of Braze only as of the date of this blog post, and Braze assumes no obligation, and does not intend to update these forward-looking statements, except as required by law.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article8 min read
Article8 min readAI decision intelligence: How smart organizations are automating better marketing decisions
June 25, 2026 Article13 min read
Article13 min readAutonomous marketing: How AI agents are transforming campaigns from manual to self-driving
June 25, 2026 Article5 min read
Article5 min readRedefining retail in the age of AI
June 25, 2026